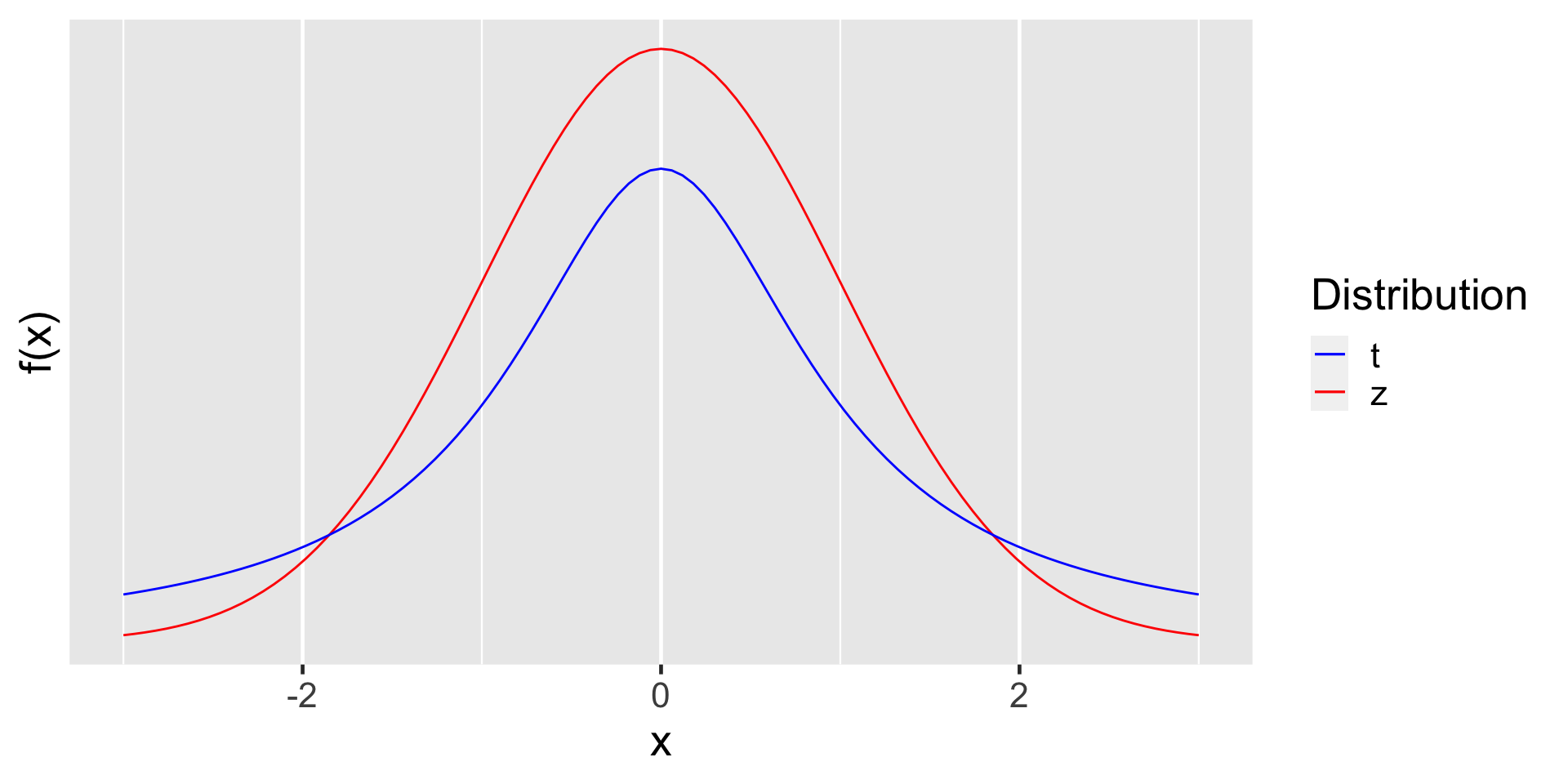
point estimate \(\pm\) critical value \(\times\) standard error
\(\bar x\)\(\pm\) critical value \(\times\) standard error
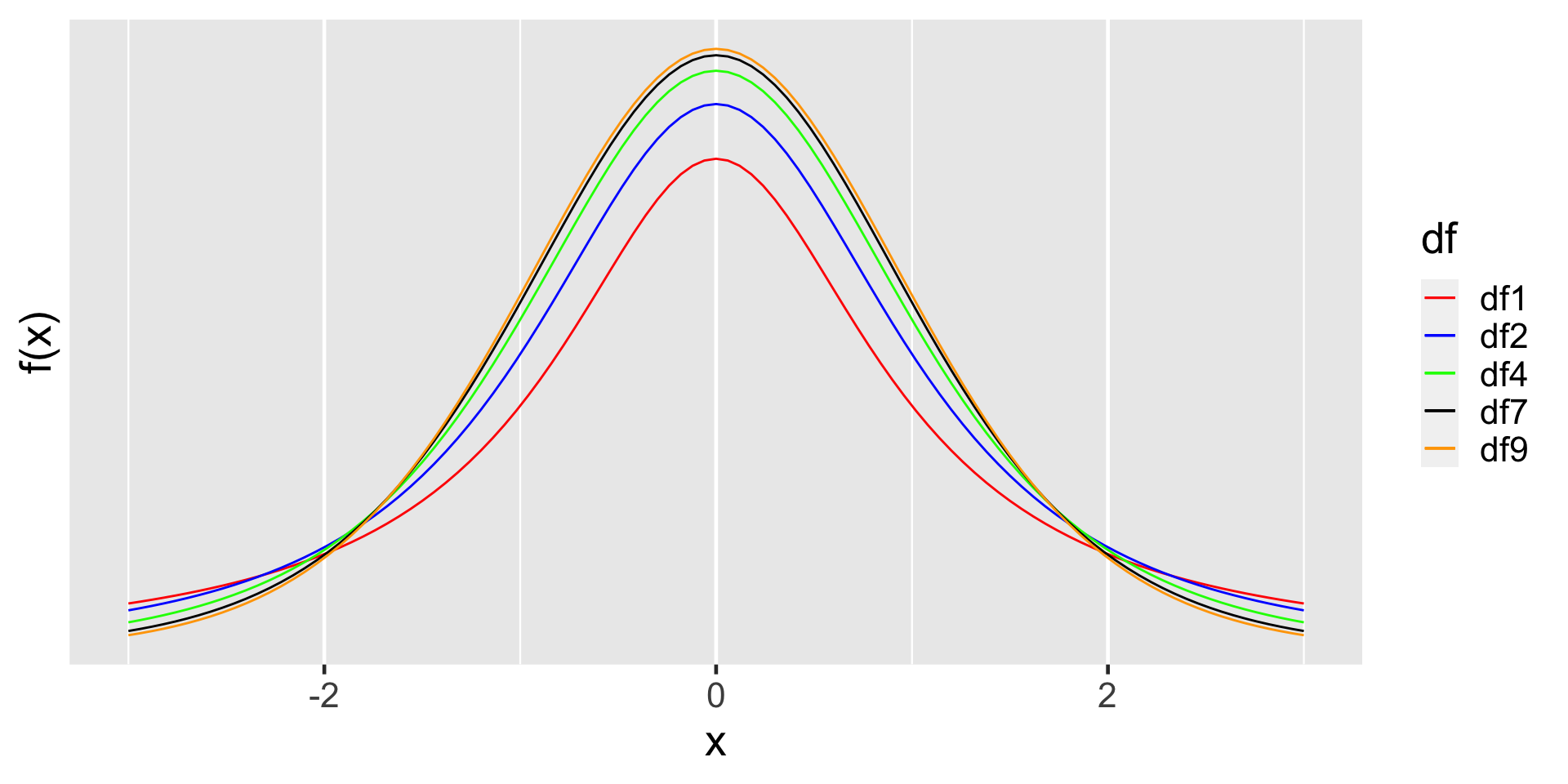
\(\bar x \pm t^*_{df}\times\) standard error
\(\bar x \pm t^*_{df} \times \frac{s}{\sqrt n}\)
Exercise
Prof. Garcia-Maldonado would like to know his average daily water intake. He records his water intake in his fitness app on his phone on 50 random days. His app shows that on average he drank 3.7 liters of water daily with standard deviation of 0.5 liters. Calculate a 95% confidence interval for average daily water intake of Prof. Garcia-Maldonado.
Conditions
Independence Despite the fact that Prof. Garcia-Maldonado has randomly selected the days he recorded data there may be possible violation of the independence condition. Consider that he selected 50 days in a two month frame. There will be many data points that are collected on consecutive days. If he has certain patterns of water drinking in a week then consecutive day data would be dependent and thus the condition of independence wuld be violated. However if he selected 50 days in a two year time frame it is possible that the data may meet the independence condition.
Normality The sample size is greater than 30. Are there any outliers in the data?
Known
\(\bar x\) = 3.7
\(s = 0.5\)
\(n = 50\)
Confidence Interval
\(\bar x \pm t^*_{df} \times \frac{s}{\sqrt n}\)
\(3.7 \pm t^*_{df} \times \frac{0.5}{\sqrt{50}}\)
Finding critical value for 95% CI when \(n = 50\)
The critical value is:
qt(0.975, df =49)
[1] 2.009575
Confidence Interval
\(3.7 \pm 2.009575 \times \frac{0.5}{\sqrt{50}}\)
se <-0.5/sqrt(50)critical_value <-qt(0.975, df =49) 3.7- critical_value*se #lower bound
[1] 3.557902
3.7+ critical_value*se #upper bound
[1] 3.842098
We are 95% confident that the average daily water in take of Prof. Garcia- Maldonado is between 3.557902 and 3.842098 liters.
Hypothesis Testing
Steps
Set hypotheses
Identify Sampling Distribution of \(H_0\)
Calculate p-value
Make a Decision and a Conclusion.
Review
To calculate the p-value
We assume the null hypothesis is true.
Based on the null hypothesis we plot/imagine the sampling distribution.
We then examine where the sample statistic falls in this distribution.
We then calculate the probability (p-value) of observing a sample statistic that is at least as extreme as the one that we have observed if the null hypothesis were true.
The American Community Survey (ACS) is an ongoing survey by the U.S. Census Bureau that is conducted to gather information on people residing in the United States. We would like to know whether those who are employed work 40 hours a week on average. The ACS results in 2012 indicate that among the 843 people who were employed, the average work hour per week was 38.9311981 hours and standard deviation was 12.9151263 hours.
\(\bar x = 38.9312\) \(s = 12.91513\) \(n = 843\)
Conditions
Independence We are not given enough information about the sampling method used for this survey. Since the aim of the survey is to gather information from people in the US and given that the survey is conducted by US Census we would expect some form of randomized sampling. However, there are sampling strategies such as cluster sampling. In such cases, a family may be selected to be surveyed. In this case, the data would not meet the independence condition. We should check US Census website to gather further information on sampling strategies. For now, we will assume independence.
Normality Sample size > 30, outliers?
Steps
Set hypotheses
Identify Sampling Distribution of \(H_0\)
Calculate p-value
Make a Decision and a Conclusion.
Step 1 : Set hypotheses
\(H_0: \mu = 40\) \(H_A: \mu \neq 40\)
Step 2: Sampling Distribution of \(H_0\)
When certain conditions are met then:
\(\bar x \sim \text{approximately } N(mean = \mu, sd =\frac{\sigma}{\sqrt{n}})\)
We will assume \(H_0\) is true
\(\bar x \sim \text{approximately } N( \text{mean} = 40, \frac{12.91513}{\sqrt{843}})\)
\(\bar x \sim \text{approximately } N(40, \text{sd} = 0.4448207)\)
Step 3: Calculate p-value
How many standard deviations (standard errors) is the point estimate away from the mean in the sampling distribution of the null hypothesis?
If the null hypothesis were true ( \(\mu = 40\) ) then probability of observing a sample statistic that is at least as extreme as the one that we have observed ( \(\bar x = 38.9312\) ) would be 0.0164871. We consider this to be an evidence against the null since p-value (0.0164871) is less than 0.05. In other words, if the null were true, it would be quite unlikely to observe a sample mean that is at least that extreme but since we have observed this sample, it is unlikely that the null is true so we reject the null and conclude that the average work time in the US in 2012 differs significantly from 40.